Using Your Own API
Tips
How to Develop Private STT / LLM / TTS Services for FoloToy Toys
1. How FoloToy AI Toys Work
All FoloToy products (including embedded boards) function as clients that connect to the toy service.
We provide the folotoy-server self-hosted Docker image, which can be deployed easily on various Linux distributions (Debian / Ubuntu / CentOS, etc.).
- Self-hosted image: https://github.com/FoloToy/folotoy-server-self-hosting
- Installation guide: https://docs.folotoy.com/zh/docs/installation/start
The folotoy-server mainly consists of the following three components:
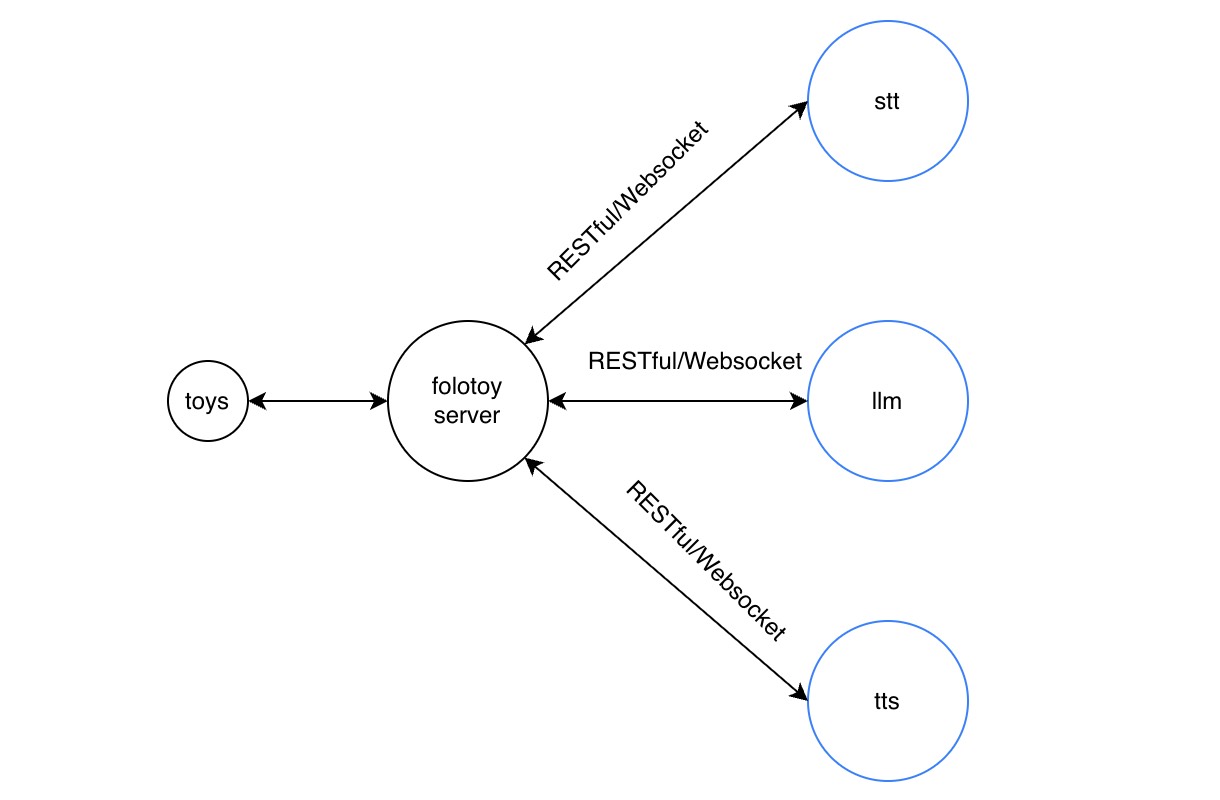
① Speech-to-Text (STT)
The server receives real-time audio streams from the toy via the internet and calls an STT API to convert sound into text.
Supported STT providers include:
- openai-whisper
- azure-stt
- azure-whisper
- dify-stt
- aliyun-asr
② Large Language Model (LLM) Generation
After receiving the transcript from STT, the server immediately calls an LLM API to obtain streaming text responses and subsequently calls a TTS service to convert the response into speech.
Supported LLM providers include:
- openai
- azure-openai
- gemini
- qianfan
- dify
- One-Api–proxied LLMs
- moonshot and other OpenAI-compatible LLMs
③ Text-to-Speech (TTS)
The toy receives MP3 audio streams generated by the server and plays them in sequence.
Supported TTS providers include:
- openai-tts
- azure-tts
- elevenlabs
- aliyun-tts
- dify-tts
- edge-tts (free)
OpenAI-Compatible API Format
All interfaces used by FoloToy toys are fully compatible with the OpenAI API specification. Therefore, once you understand the workflow, you only need to provide OpenAI-style RESTful STT/LLM/TTS interfaces, and the toy will be able to use your customized services.
2. Implementing and Using Custom Services
After implementing OpenAI-compatible services, you can enable them by modifying:
docker-compose.yml(global configuration)roles.json(role-specific configuration; higher priority)
2.1 Custom STT Service
API Specification
Reference OpenAI STT API: https://platform.openai.com/docs/api-reference/audio/createTranscription
Base URL
http://api.your_company.com/v1
Path
/audio/transcriptions
Method
POST
Parameters
| Parameter | Required | Description |
|---|---|---|
| file | Yes | Audio file |
| model | Yes | whisper-1 or your custom model |
| language | Optional | |
| prompt | Optional | |
| response_format | Optional | |
| temperature | Optional | |
| timestamp_granularities[] | Optional |
Example Request (cURL)
curl http://api.your_company.com/v1/audio/transcriptions \
-H "Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxx" \
-H "Content-Type: multipart/form-data" \
-F file="@/path/to/file/audio.mp3" \
-F model="whisper-1"
folotoy-server Configuration Example
STT_TYPE: openai-whisper
OPENAI_WHISPER_API_BASE: http://api.your_company.com/v1
OPENAI_WHISPER_KEY: sk-xxxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_WHISPER_MODEL: whisper-1
After modifying:
sudo docker compose up -d
Reference Implementations
- Faster-Whisper (OpenAI API compatible): https://github.com/lewangdev/faster-whisper/blob/master/openaiapi.py
- Alibaba SenseVoice: https://github.com/lewangdev/SenseVoice/blob/main/openaiapi.py
2.2 Custom LLM Service
Reference OpenAI Chat Completion API: https://platform.openai.com/docs/api-reference/chat/create
Note: The toy service only supports streaming responses (stream: true).
Base URL
http://api.your_company.com/v1
Path
/chat/completions
Method
POST
Parameters
| Parameter | Required | Description |
|---|---|---|
| messages | Yes | Standard OpenAI chat format |
| model | Yes | Your custom model name |
| max_tokens | Optional | Default 200 |
| stream | Must be true | Only true is supported |
| response_format | Optional | json |
| temperature | Optional | Default 0.7 |
Example Request
curl http://api.your_company.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxx" \
-d '{
"model": "your_model_name",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": true
}'
folotoy-server Configuration
LLM_TYPE: openai
OPENAI_OPENAI_API_BASE: http://api.your_company.com/v1
OPENAI_OPENAI_MODEL: your_model_name
OPENAI_OPENAI_KEY: sk-xxxxxxxxxxxxxxxxxxxxxxxxx
Update with:
sudo docker compose up -d
Reference Implementation
- ChatGLM3 (OpenAI API compatible): https://github.com/THUDM/ChatGLM3/blob/main/openai_api_demo/api_server.py
2.3 Custom TTS Service
Reference OpenAI TTS API: https://platform.openai.com/docs/api-reference/audio/createSpeech
Base URL
http://api.your_company.com/v1
Path
/audio/speech
Method
POST
Parameters
| Parameter | Required | Description |
|---|---|---|
| model | Yes | Custom model name, e.g., tts-100 |
| input | Yes | Text to synthesize |
| voice | Yes | Voice name, e.g., guodegang |
| speed | Optional | Range: 0.25–4.0 |
| response_format | Must be mp3 | Toy only plays mp3 |
Example Request
curl https://api.openai.com/v1/audio/speech \
-H "Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "tts-100",
"input": "The quick brown fox jumped over the lazy dog.",
"voice": "guodegang"
}' \
--output speech.mp3
folotoy-server Configuration
TTS_TYPE: openai-tts
OPENAI_TTS_API_BASE: http://api.your_company.com/v1
OPENAI_TTS_KEY: sk-xxxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_TTS_MODEL: tts-100
OPENAI_TTS_VOICE_NAME: guodegang
Update with:
sudo docker compose up -d
Reference Implementations
- EmotiVoice (Netease): https://github.com/netease-youdao/EmotiVoice/blob/main/openaiapi.py
- CosyVoice (Alibaba): https://github.com/lewangdev/CosyVoice/blob/main/openaiapi.py
- OpenVoice (MyShell): https://github.com/lewangdev/OpenVoice/blob/v1/openaiapi.py