使用自己实现的 API
提示
如何开发 FoloToy 玩具可使用的私有 STT / LLM / TTS 服务
1. FoloToy AI 玩具是如何工作的?
FoloToy 出品的所有玩具(包括电路板)作为客户端连接玩具服务。
我们提供 folotoy-server 的 自部署 Docker 镜像,可以轻松部署在各种 Linux 系统上(Debian / Ubuntu / CentOS 等)。
- 自部署镜像:https://github.com/FoloToy/folotoy-server-self-hosting
- 部署教程:https://docs.folotoy.com/zh/docs/installation/start
folotoy-server 主要由 3 个部分组成:
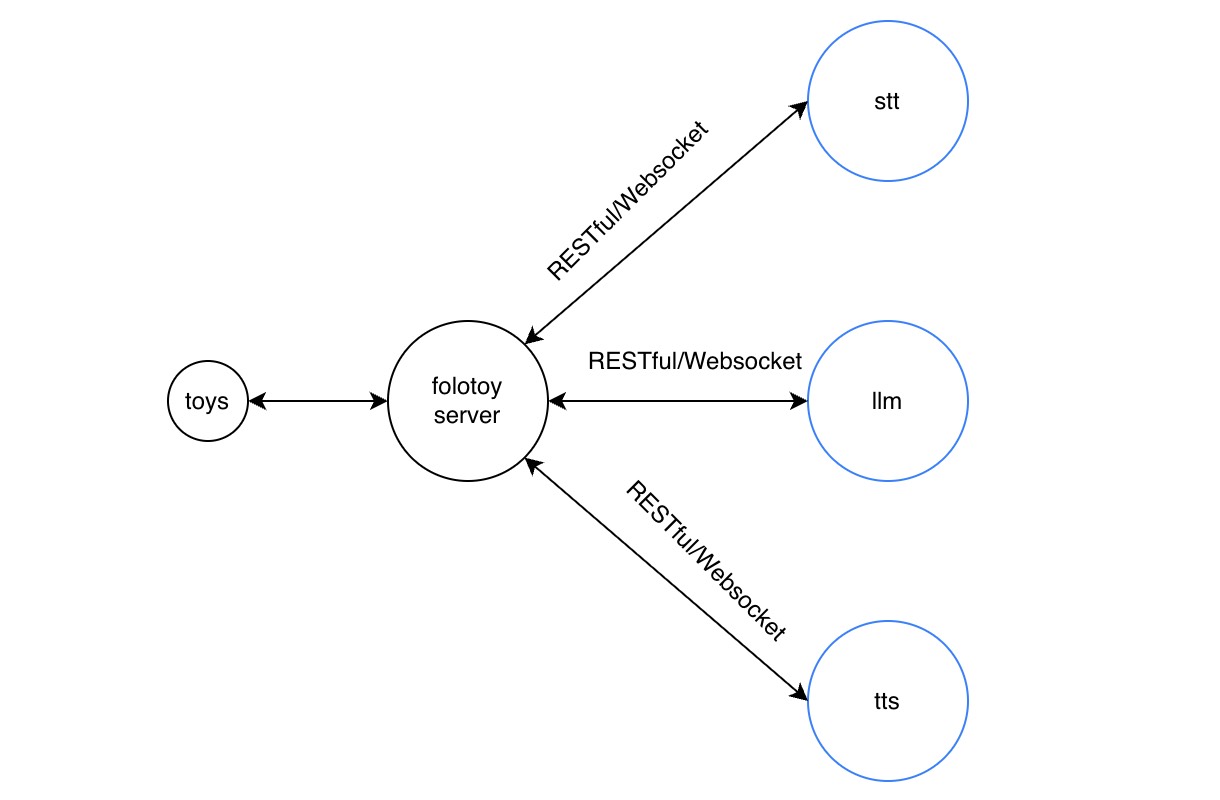
① 语音转文本(STT)
服务端通过公网接收玩具发送的实时录音数据,并调用 STT API 转成文本。
支持的 STT:
- openai-whisper
- azure-stt
- azure-whisper
- dify-stt
- aliyun-asr
② 调用大模型生成文本(LLM)
收到 STT 文本后,服务端立即调用 LLM API 获取流式回复,然后调用 TTS 转语音。
支持的 LLM:
- openai
- azure-openai
- gemini
- qianfan
- dify
- One-Api 代理模型
- moonshot 等 OpenAI 接口兼容模型
③ 文本转语音(TTS)
玩具端接收服务器返回的 MP3 语音流并播放。
支持的 TTS:
- openai-tts
- azure-tts
- elevenlabs
- aliyun-tts
- dify-tts
- edge-tts(免费)
接口兼容方式
FoloToy 玩具调用的接口 完全兼容 OpenAI API 格式。 因此,只需提供一个与 OpenAI 风格一致的 RESTful STT / LLM / TTS 接口,即可让玩具使用你自定义的服务。
2. 实现并调用自定义服务
自定义服务通过修改:
docker-compose.yml(全局)roles.json(角色级别,优先级更高)
即可配置使用。
2.1 自定义 STT 服务
接口说明
参考 OpenAI STT: https://platform.openai.com/docs/api-reference/audio/createTranscription
Base URL
http://api.your_company.com/v1
Path
/audio/transcriptions
Method
POST
参数
| 参数 | 必须 | 说明 |
|---|---|---|
| file | 必须 | 音频文件 |
| model | 必须 | 如 whisper-1 或自定义名称 |
| language | 可选 | |
| prompt | 可选 | |
| response_format | 可选 | |
| temperature | 可选 | |
| timestamp_granularities[] | 可选 |
示例调用(curl)
curl http://api.your_company.com/v1/audio/transcriptions \
-H "Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxx" \
-H "Content-Type: multipart/form-data" \
-F file="@/path/to/file/audio.mp3" \
-F model="whisper-1"
folotoy-server 配置示例
STT_TYPE: openai-whisper
OPENAI_WHISPER_API_BASE: http://api.your_company.com/v1
OPENAI_WHISPER_KEY: sk-xxxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_WHISPER_MODEL: whisper-1
修改完成后:
sudo docker compose up -d
参考实现
- Faster-Whisper(兼容 OpenAI API): https://github.com/lewangdev/faster-whisper/blob/master/openaiapi.py
- 阿里 SenseVoice: https://github.com/lewangdev/SenseVoice/blob/main/openaiapi.py
2.2 自定义 LLM 服务
参考 OpenAI 接口: https://platform.openai.com/docs/api-reference/chat/create
要求:必须支持流式(stream=true)。
Base URL
http://api.your_company.com/v1
Path
/chat/completions
Method
POST
参数
| 参数 | 必须 | 说明 |
|---|---|---|
| messages | 必须 | 标准 chat 格式 |
| model | 必须 | 自定义模型名称 |
| max_tokens | 可选 | 默认 200 |
| stream | 必须为 true | 玩具仅支持流式 |
| response_format | 可选 | json |
| temperature | 可选 | 默认 0.7 |
示例调用
curl http://api.your_company.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxx" \
-d '{
"model": "your_model_name",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": true
}'
folotoy-server 配置
LLM_TYPE: openai
OPENAI_OPENAI_API_BASE: http://api.your_company.com/v1
OPENAI_OPENAI_MODEL: your_model_name
OPENAI_OPENAI_KEY: sk-xxxxxxxxxxxxxxxxxxxxxxxxx
更新服务:
sudo docker compose up -d
参考实现
- ChatGLM3(兼容 OpenAI API): https://github.com/THUDM/ChatGLM3/blob/main/openai_api_demo/api_server.py
2.3 自定义 TTS 服务
参考 OpenAI TTS: https://platform.openai.com/docs/api-reference/audio/createSpeech
Base URL
http://api.your_company.com/v1
Path
/audio/speech
Method
POST
参数
| 参数 | 必须 | 说明 |
|---|---|---|
| model | 必须 | 自定义模型名称,如 tts-100 |
| input | 必须 | 要转换的文本 |
| voice | 必须 | 声音名称,如 guodegang |
| speed | 可选 | 0.25–4.0 |
| response_format | 必须为 mp3 | 玩具仅支持 mp3 |
示例调用
curl https://api.openai.com/v1/audio/speech \
-H "Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "tts-100",
"input": "The quick brown fox jumped over the lazy dog.",
"voice": "guodegang"
}' \
--output speech.mp3
folotoy-server 配置
TTS_TYPE: openai-tts
OPENAI_TTS_API_BASE: http://api.your_company.com/v1
OPENAI_TTS_KEY: sk-xxxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_TTS_MODEL: tts-100
OPENAI_TTS_VOICE_NAME: guodegang
更新服务:
sudo docker compose up -d
参考实现
- EmotiVoice(网易开源): https://github.com/netease-youdao/EmotiVoice/blob/main/openaiapi.py
- CosyVoice(阿里开源): https://github.com/lewangdev/CosyVoice/blob/main/openaiapi.py
- OpenVoice(MyShell 开源): https://github.com/lewangdev/OpenVoice/blob/v1/openaiapi.py